printf("Der Wert von Variable 'a' ist jetzt %d.\n", a);
Was meint ihr, gelingt es mir als Programmierer von BoeseFunktion() dass die Ausgabe in der zweiten Zeile Der Wert von Variable 'a' ist jetzt 0. lautet? Selbst wenn 'a' nur lokal der Main-Funktion bekannt ist?
Ich sage ja:
BoeseFunktion():
void BoeseFunktion(int tmp) {
int* pointer;
pointer = &tmp - 1;
*pointer = *pointer + 8;
}
Das funktioniert eigentlich ganz einfach. Mit pointer = &tmp - 1; hole mich mir einen Zeiger auf den ersten Funktionsparameter und reduziere die Adresse um 1. Auf x86-Systemen bin ich nun an der Rücksprungadresse von BoeseFunktion() auf dem Stack.
So sieht das im Speicher aus:
Und mit *pointer = *pointer + 8; erhöhe ich anschließend die Rücksprungadresse um 8 Byte, was gerade soviel ist um das a = 1; in main() zu überspringen.
Solches Gehacke mit Pointer-Arithmetik ist natürlich sowieso pfui. Aber was uns dieses Beispiel eigentlich lehren soll ist, dass man fremden Funktionen nicht trauen soll.
Es könnte schließlich sein, dass ich sie geschrieben habe... 😉
Schadensabwehr
Aber wie bekommt man nun das Problem in den Griff, dass Fremdcode, den man in so gut wie jedem Projekt findet, unbeabsichtigt oder beabsichtigt Unfug anstellt und Daten oder die Programmausführung beeinträchtigt?
Da gibt es mehrere Möglichkeiten. Unter anderem:
Logische Programmablaufkontrolle
Man stelle sich vor, jede eigene Funktion meldet sich bei ihrem Aufruf an einer zentralen Instanz mit einem eindeutigen Key. Die zentrale Instanz überprüft dann anhand einer Tabelle ob es in Ordnung ist, dass Funktion3 nun auf Funktion2 folgt oder nicht.
Bringt fremder Code - zum Beispiel eine defekte DLL - den Ablauf durcheinander so wird dies schnell aufgedeckt.
Voraussetzung für ein solches System ist natürlich eine deterministische Reihenfolge der Funktionsaufrufe.
Datenredundanz
Zuerst einmal sollten alle Daten, die irgendwie wichtig sind, redundant vorliegen; am besten redundant-invers. Das heißt, es gibt nicht eine Variable 'a', sondern z.B. 'unsigned char u8VentilSollwert' und 'unsigned char u8VentilSollwertInvers'. Das hat nicht nur einen eingängigeren Namen als 'a' sondern informiert uns auch gleich noch über das Präfix u8, dass es eine unsigned 8-Bit-Variable ist mit Wertebereich von 0..255.
In der einen steht dann z.B. 1 (binär 0000 0001) und in der anderen das Gegenteil, also 254 (1111 1110).
Vor Verwendung wird jedes Mal geprüft, ob die beiden Variablen noch Bit-invers sind und falls nicht mit Fehlermeldung abgebrochen.
Datensicherung
Wenn die Daten umfangreicher sind, gibt es die Möglichkeit sie mit einer Checksumme zu sichern. Wird die Checksumme oder die Daten beschädigt, so fällt dies auf, sobald man die Checksumme nachrechnet und mit dem Prüfwert vergleicht.
calDAV und iCalendar code example mit Qt, C++ und QML
Nachdem ich mich letztes Jahr schon hier und da mit Kalendern für Webseiten und dem iCalendar-Format beschäftigt hatte, habe ich letztens während dem 33C3 in Hamburg noch einen calDAV-Client in C++ und QML mit Qt geschrieben.
Zweck: den Küchen-Computer um eine Kalenderansicht mit meinen anstehenden Terminen erweitern.
Da ich keinen passenden Beispielcode finden konnte, der nicht entweder nur ansatzweise funktioniert oder völlig overfeatured ist, habe ich kurzerhand anhand der offiziellen Spezifikation selbst etwas geschrieben:
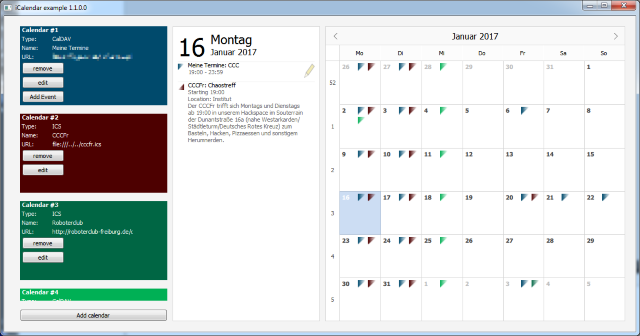
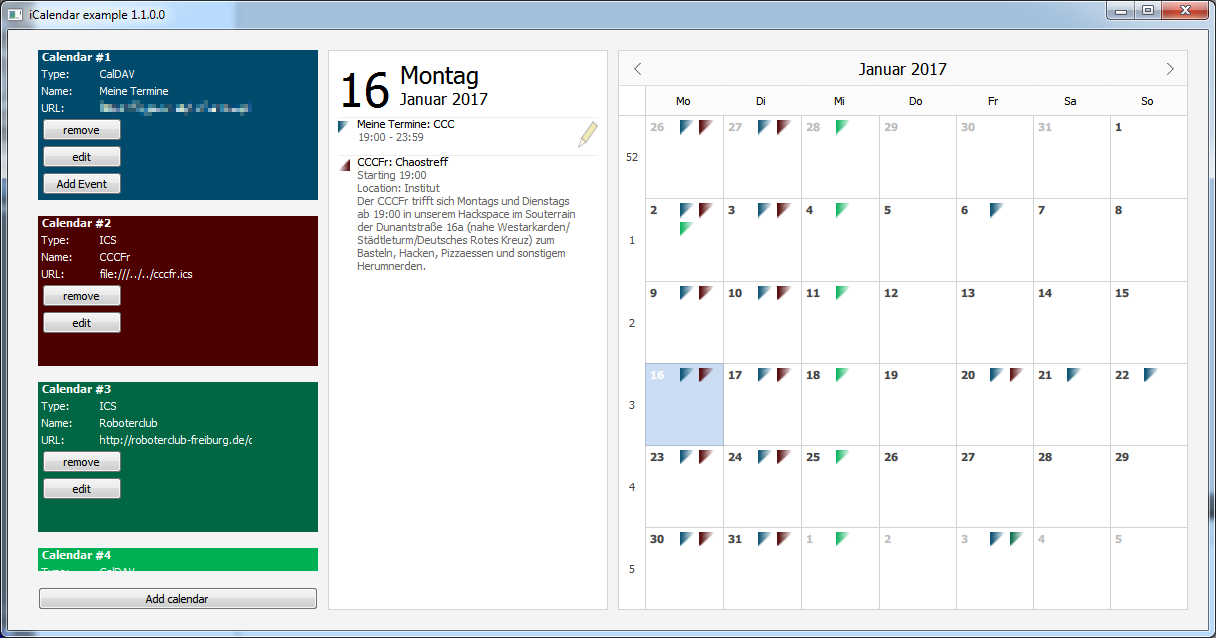
GUI-Screenshot des Beispielprojekts
Features (u.a.):
Wenn man in Qt eine Klasse implementiert, sollte man tunlichst darauf achten, dass alle instantiierten Attribute this als parent haben.
Andernfalls kann es nämlich sein, dass irgendwann der Garbage-Kollektor auf das offenbar elternlose Kind-Objekt stößt und es im Sinne von "ist das Kunst oder kann das weg" in die Tonne wirft.
Und dann hat man den Salat.
Ist mir hiermit passiert:
classMeasurement : publicObject
{
Q_OBJECT
public:
Measurement(QObject* parent = 0);
~Measurement();
};
classXYPlot : publicQQuickPaintedItem
{
Q_OBJECT
public:
XYPlot(QQuickPaintedItem* parent = 0);
private:
Measurementm_Measurement;
};
Das Elternelement hier ist XYPlot, welches ein Attribut der Klasse Measurement besitzt.
Bei mir gab es unreproduzierbare SIGSEGV segmentation faults, was immer auf irgendein Problem mit ungültigem Pointer hinweist.
Beim Debuggen habe ich dann festgestellt, dass kurz zuvor der Dekonstruktor von Measurement aufgerufen wurde - obwohl das zugehörige XYPlot-Objekt noch existierte.
Woran lag es? ⇒ Ich hatte vergessen, dem Kind-Objekt zu sagen wer sein parent ist. Im Konstruktor der Elternklasse XYPlot also m_Measurement mit this instantiieren:
 Und mit
Und mit